| Index | Thell | Documents | Links | About |
偙偺儁乕僕偱偼丄儕僶乕僔僾儘僌儔儉Thell偺巚峫僄儞僕儞"spot"偱巊傢傟偰偄傞傾儖僑儕僘儉偵偮偄偰夝愢偟傑偡丅儕僶乕僔僾儘僌儔儈儞僌偵偮偄偰偁傞掱搙偺棟夝偲宱尡偑偁傞偙偲傪慜採偲偟偰偄傑偡偺偱丄弶傔偰偺曽偼嶲峫暥專偵偁傞傛偆側暥彂傪嶲徠偡傞偙偲偐傜巒傔傞偲傛偄偱偟傚偆丅
Thell偺儃乕僪偼Board偲偄偆僋儔僗偱偡丅偙偺僋儔僗偼旕忢偵戝婯柾偱崅婡擻側僋儔僗偱偡偑丄儃乕僪杮懱偼Color宆(幚懱偼int)偺2師尦攝楍偲側偭偰偄傑偡丅
儃乕僪偺愝寁偵偍偄偰戝偒側榑揰偲側傞偺偑move/undo偺幚憰偱偡丅僎乕儉栘扵嶕偱偼怺偝桪愭偱拝庤偲庢傝徚偟傪昿斏偵峴偆偨傔丄偙偺張棟傪偄偐偵崅懍偵峴偆偐偑廳梫偵側偭偰偒傑偡丅1偮偼丄拝庤帪偵儃乕僪偺僐僺乕傪惗惉偟偰僐僺乕偵懳偟偰拝庤憖嶌傪峴偄丄庢傝徚偟帪偵偼僐僺乕傪攋婞偡傞僐僺乕曽幃丅傕偆1偮偼拝庤偵嵺偟偰曄峏揰傪婰榐偟偰僗僞僢僋偵愊傒丄庢傝徚偟帪偵偼僗僞僢僋偺棜楌傪尦偵曄峏揰偩偗傪彂偒栠偡嵎暘曽幃丅慜幰偱偼僐僺乕偵偐偐傞僐僗僩偑丄屻幰偱偼僗僞僢僋憖嶌偵偐偐傞僐僗僩偑栤戣偲側傝傑偡丅
Thell偱偼丄嵎暘曽幃傪嵦梡偟偰偄傑偡丅偙傟偼丄1夞偺拝庤偱彂偒姺傢傞売強偼偦傟傎偳懡偔側偄偨傔丄儃乕僪慡懱傪僐僺乕偡傞傛傝傕嵎暘傪庢偭偨曽偑張棟偑寉偄偩傠偆偲偄偆敾抐偵埶傝傑偡丅
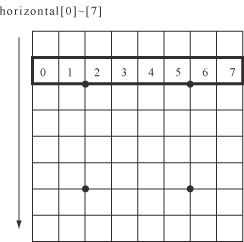
嬤擭偺儕僶乕僔僾儘僌儔儈儞僌嬈奅偱忢幆偲側偭偰偄傞庤朄偵僀儞僨僢僋僗偺棙梡偑偁傝傑偡丅偙傟偼丄曈偺愇偺攝抲側偳傪晞崋壔偟偰堦堄偺惍悢抣偱昞尰偡傞庤朄偱偡丅椺偊偽悈暯曽岦偺堦曈偺8愇偺暲傃傪峫偊偨応崌丄偦傟偧傟偺儅僗偵偮偄偰崟丄敀丄嬻偒偺3捠傝偺応崌偑偁傞偺偱丄3^8 = 6561捠傝偺惍悢偱奺乆偺攝抲傪晞崋壔偱偒傞偙偲偵側傝傑偡丅
椺偊偽丄悈暯曈偺2斣栚丄horizontal[1]偼埲壓偺傛偆側曈傪昞偟偰偍傝丄0,1,2...偲帵偟偨儅僗偺怓偵懳偟偰black = 2, empty = 1, white = 0偱晞崋壔傪峴偄丄i斣栚(i=0,...,7)偺儅僗偺晞崋偵懳偟偰3偺i忔傪偐偗偰壛偊偨悢偑僀儞僨僢僋僗偱偡丅
僀儞僨僢僋僗傪梡偄傞偲壗偑偆傟偟偄偐偲偄偆偲丄儕僶乕僔偺斦柺憖嶌偵棈傓傾儖僑儕僘儉偼奺乆偺曈偵偮偄偰撈棫偱偁傞偙偲偑懡偔丄憖嶌寢壥傪帠慜偵寁嶼偟偰偍偄偰昞偵奿擺偟偰偍偒丄曈偺僀儞僨僢僋僗偐傜寢壥偩偗傪庢偭偰偔傞丄偲偄偆憖嶌偑壜擻偵側傞偙偲偱偡丅
Thell偱偼丄Indexer偲偄偆僋儔僗偑儃乕僪偺僀儞僨僢僋僗傪曐帩偟偰偄傑偡丅僀儞僨僢僋僗偼丄悈暯*8屄丄悅捈*8屄丄幬傔曈*11屄偑2曽岦丄偺崌寁38屄偱偡丅幬傔曈偑11屄側偺偼丄挿偝1偲挿偝2偺幬傔曈偼拝庤偵娭學側偄(偙偺曽岦偵愇傪嫴傫偱曉偡偙偲偼偱偒側偄)偨傔丄徣偄偰偄傞偙偲偵傛傝傑偡丅挿偝偑8偵枮偨側偄幬傔曈偺応崌偼丄儅僗偑懚嵼偟側偄売強傪嬻儅僗偲尒側偡偙偲偵傛偭偰丄悈暯丒悅捈曈偺応崌偲摨條偵拝庤壜擻偐偳偆偐傪挷傋傜傟傞傛偆偵偟偰偄傑偡丅
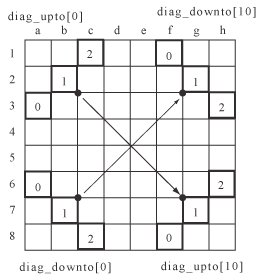
拝庤偵傛偭偰愇偑曉偭偨偲偒偼丄塭嬁傪庴偗傞(抣偑曄壔偡傞)僀儞僨僢僋僗偵偮偄偰偺傒丄嵎暘傪寁嶼偟偰僀儞僨僢僋僗抣傪峏怴偟傑偡丅
拝庤偵嵺偟偰丄僀儞僨僢僋僗傪棙梡偟傑偡丅偳偺曽岦偵壗屄愇偑曉偣傞偐丄曉偣側偄偐偼幚嵺偵8曽岦傪挷傋偰傒側偄偲傢偐傜側偄傢偗偱偡偑丄偙傟偼曈偛偲偵撈棫偵挷傋傞偙偲偑偱偒傞偨傔丄慡偰偺愇偺暲傃曽偵偮偄偰偳偙偵愇傪抲偄偨傜壗愇曉偣傞偐傪帠慜偵挷傋偰昞偵偟偰偍偔偙偲偑偱偒傑偡丅偙傟偑拝庤壜擻昞(mobility table)偱偡丅曈偺愇偺暲傃曽偼崅乆3^8 = 6561捠傝側偺偱丄昞偺峔抸偼堦弖偱偱偒傑偡丅
偮傑傝丄拝庤壜擻偐偳偆偐挷傋傞偵偼丄8曽岦偵偮偄偰
傪挷傋傟偽傛偄偙偲偵側傝傑偡丅
(偦偺傑傑幚憰/bitboard)
埲慜偺spot偺儃乕僪偺幚憰偱偼丄STL偺vector傪懡梡偟偨峔憿偵側偭偰偄傑偟偨丅尰嵼偼偙傟傪帺暘偱嶌偭偨娙堈vector僋儔僗偵抲偒姺偊偰偄傑偡丅偦傟偼丄彮側偔偲傕Visual C++ .NET 2003偵晅懏偡傞STL偺幚憰偼晠偭偰偍傝丄clear()帪偵儊儌儕傪夝曻偡傞偨傔丄廳偡偓偰巊偭偰偄傜傟側偄偨傔偱偡丅clear()偱偼儊儌儕傪夝曻偟側偄傛偆偵寛傑偭偰偄傞偼偢偱偡偑乧乧丅
扵嶕傾儖僑儕僘儉偵偼丄斀暅怺壔偡傞negamax斉alpha-beta傪梡偄偰偄傑偡丅扵嶕栘偺崻偵嬤偄曽偱偼丄PVS(Pricipal Variation Search)傪巊偭偰偄傑偡丅
PVS偼null window search傪峴偭偰張棟偺崅懍壔傪恾傞揰偱NegaScout偲杮幙揑偵偼摨偠偱偡偑丄乽alpha-beta window傪枮偨偡抣(principal variation)傪尒偮偗傞傑偱偼null window search傪峴傢側偄乿偲偄偆晹暘偑堘偄偱偟傚偆偐丅巕僲乕僪偼嵟慞庤弴偵move ordering偝傟偰偄傞偲偄偆慜採偺傕偲丄principal variation傪尒偮偗偨屻偼null window search偵傛偭偰principal variation傛傝埆偄偙偲偺傒傪妋擣偟傑偡丅傕偪傠傫move ordering偑忢偵姰帏偲偼尷傝傑偣傫偐傜丄principal variation敪尒屻偵偦傟埲崀偺僲乕僪偱傛傝傛偄抣傪敪尒偡傞壜擻惈偑偁傝傑偡丅偦偺応崌偼丄null window search偺傒偱偼晄廫暘偱丄window傪杮棃偺暆偵偟偰嵟扵嶕傪峴偄傑偡丅偦偺偁偨傝偺巇慻傒偼NegaScout偲慡偔摨偠偱偡丅
扨弮側alpha-beta偲PVS偺惈擻嵎偵偮偄偰娙扨側斾妑應掕傪偟偰傒傑偟偨丅(Pentium4 3GHz偵偍偗傞應掕)
| 傾儖僑儕僘儉 | 撪晹僲乕僪悢 | 梩僲乕僪悢 | 慡扵嶕僲乕僪悢 | 帪娫(昩) |
|---|---|---|---|---|
| alpha-beta | 8,874,253 (1.0) | 16,330,773 (1.0) | 25,205,026 (1.0) | 23.36 (1.0) |
| PVS | 7,214,182 (0.81) | 12,656,360 (0.78) | 19,870,542 (0.79) | 19.938 (0.85) |
| 傾儖僑儕僘儉 | 撪晹僲乕僪悢 | 梩僲乕僪悢 | 慡扵嶕僲乕僪悢 | 帪娫(昩) |
|---|---|---|---|---|
| alpha-beta | 20,889,941 (1.0) | 7,110,837 (1.0) | 28,000,778 (1.0) | 13.906 (1.0) |
| PVS | 18,670,966 (0.89) | 6,338,665 (0.89) | 25,009,631 (0.89) | 11.718 (0.84) |
| 傾儖僑儕僘儉 | 撪晹僲乕僪悢 | 梩僲乕僪悢 | 慡扵嶕僲乕僪悢 | 帪娫(昩) |
|---|---|---|---|---|
| alpha-beta | 60,288,739 (1.0) | 20,688,886 (1.0) | 80,977,625 (1.0) | 40.656 (1.0) |
| PVS | 37,243,908 (0.62) | 12,446,931 (0.60) | 49,690,839 (0.61) | 25.625 (0.63) |
| 傾儖僑儕僘儉 | 撪晹僲乕僪悢 | 梩僲乕僪悢 | 慡扵嶕僲乕僪悢 | 帪娫(昩) |
|---|---|---|---|---|
| alpha-beta | 82,945,965 (1.0) | 28,375,754 (1.0) | 111,321,719 (1.0) | 52.219 (1.0) |
| PVS | 43,904,598 (0.53) | 14,822,248 (0.54) | 58,726,846 (0.53) | 28.203 (0.54) |
妵屖撪偺悢抣偼丄alpha-beta偵傛傞抣傪1.0偲偟偨偲偒偺PVS偺抣傪昞偟傑偡丅PVS偺嵦梡偵傛偭偰拞斦偱偼栺15%丄廔斦偱偼15乣45%嬤偔扵嶕帪娫傪抁弅偱偒偰偄傑偡丅
alpha-beta扵嶕偑扨弮側minimax扵嶕偵懳偟偰惈擻傪忋偘傜傟傞偺偼丄傛偄巬偐傜弴偵扵嶕傪峴偭偨偲偒偱偡丅媡偵埆偄巬偐傜弴偵昡壙偟偨応崌偼minimax偲摨偠惈擻偟偐摼傜傟傑偣傫丅偙偺偨傔丄扵嶕懍搙傪忋偘傞偨傔偵偼巬傪昡壙偡傞弴斣偑偒傢傔偰廳梫偱偡丅偙偺暲傃懼偊傪move ordering偲尵偄傑偡丅
Thell偱偼丄斀暅怺壔傪偆傑偔棙梡偟偰庤傪暲傋懼偊偰偄傑偡丅嬶懱揑偵偼丄抲姺昞(屻弎)傪2枃梡堄偟偰偍偒丄曅曽偵慜夞(堦抜愺偄扵嶕)偺扵嶕偵偍偗傞抲姺昞傪擖傟丄傕偆曅曽傪崱夞偺扵嶕偺抲姺昞偲偟偰巊偄傑偡丅
慜夞偺抲姺昞偵懚嵼偟偰偄傞嬊柺偼丄慜夞巬姞傝偝傟側偐偭偨嬊柺偱偁傝丄傛偄庤偱偁傞壜擻惈偑崅偄嬊柺偱偡丅廬偭偰丄慜夞偺抲姺昞偵懚嵼偡傞嬊柺偐傜桪愭偟偰扵嶕傪峴偄傑偡丅慜夞偺抲姺昞偵懚嵼偟側偐偭偨嬊柺偵偮偄偰偼丄惷揑昡壙娭悢偵傛傞昡壙抣偱暲傋懼偊偰偍偒傑偡丅
move ordering偵梡偄傞惷揑昡壙娭悢偼丄彉斦乣拞斦偱偼昡壙娭悢偦偺傕偺丄廔斦偱偼懍偝桪愭扵嶕(屻弎)偺偨傔偵拝庤壜擻庤悢傪悢偊傞娭悢偲偟偰偄傑偡丅
move ordering偺幚憰偼AlphaBetaAI::sort(AI.cpp)偵偁傝傑偡丅
斀暅怺壔偺傾儖僑儕僘儉偼埲壓偺傛偆偵側傝傑偡丅幚憰偼AlphaBetaAI::moveMidGame媦傃AlphaBetaAI::moveEndGame(偲傕偵AI.cpp)偵偁傝傑偡丅
抲姺昞A(慜夞梡), B(崱夞梡)傪梡堄;
int d = 弶婜抣; // 4偲偐
do {
alphabeta(d, -亣, +亣);
swap (A, B); // 抲姺昞偺栶妱傪岎姺
d++;
} while (d <= 嵟廔揑側愭撉傒庤悢);
廔斦偼僐儞僺儏乕僞儕僶乕僔偑嵟傕摼堄偲偡傞暘栰偱偡丅廔斦姰慡撉傒愗傝偼(惓偟偔幚憰偝傟偰偄傟偽)乽愨懳偵庤傪娫堘偆偙偲偑側偄乿偨傔丄怺偄廔斦撉傒愗傝傪崅懍偱峴偊傞偙偲偼嫮偝偵捈寢偟傑偡丅spot偼丄廔斦偱偼埲壓偺傛偆側岺晇偵傛偭偰扵嶕懍搙傪忋偘偰偄傑偡丅
move ordering傗抲姺昞偵傛傞巬姞傝偼扵嶕僲乕僪悢傪尭彮偝偣傑偡偑丄偦偺暘梋寁側僐僗僩偑偐偐傝傑偡丅僎乕儉栘偺梩偵嬤偄晹暘偱偼丄move ordering偺僐僗僩偑巬姞傝偵傛偭偰嶍尭偱偒傞帪娫揑僐僗僩傪忋夞傞応崌傕偁傝傑偡丅偙偺偨傔丄梩偐傜堦掕偺崅偝埲撪偵偁傞僲乕僪偱偼move ordering傗抲姺昞傊偺搊榐丒専嶕傪峴傢側偄傛偆偵偟偰丄扵嶕懍搙傪忋偘偰偄傑偡丅偙偺崅偝偲偟偰丄拞斦偱偼3丄廔斦偱偼7傪梡偄偰偄傑偡丅偙傟傜偼幚尡揑偵寛掕偝傟偨抣偱丄昡壙娭悢傗儃乕僪昞尰偺幚憰偵傛偭偰懡彮忋壓偟傑偡丅
側偍丄spot偱偼偙偺愗傝懼偊抧揰傪嫬偵PVS偲扨弮alpha-beta傪愗傝懼偊偰偄傑偡丅偡側傢偪丄
偺傛偆偵扵嶕庤朄傪慻傒崌傢偣偰崅懍壔傪偼偐傝傑偡丅
扵嶕傾儖僑儕僘儉偼偲偵偐偔崅懍偱偁傟偽偁傞傎偳朷傑偟偄偺偼尵偆傑偱傕偁傝傑偣傫丅帋崌偵傛偭偰偼帩偪帪娫偑惂尷偝傟偰偄傞応崌傕偁傝丄扵嶕偑崅懍偩偲偦傟偩偗怺偔撉傓偙偲偑偱偒丄嫮偝偵偮側偑傝傑偡丅
奐敪偺嵟弶偺抜奒偱偼傑偢僶僌側偔幚憰偡傞偙偲丄昡壙娭悢偺惛搙傪忋偘傞偙偲偑廳梫偱偡偑丄偦傟傜偑堦抜棊偟偨傜扵嶕懍搙偺僠儏乕僯儞僌傪峴偆偲傛偄偱偟傚偆丅懍搙岦忋偺偨傔偵偼傑偢巬姞傝傪岺晇偡傞偙偲偱偡丅傛傝傛偄move ordering傪崅懍偱幚尰偡傞偨傔偺庤朄傪峫偊傑偟傚偆丅
僠儏乕僯儞僌偺偨傔偵丄寛傑偭偨僥僗僩働乕僗傪梡堄偟偰儀儞僠儅乕僋傪峴偄丄強梫帪娫偲扵嶕僲乕僪悢偺婰榐傪庢傝傑偡丅扵嶕僲乕僪悢偐傜巬姞傝惈擻偑丄nps(node per second: 1昩偁偨傝偺扵嶕僲乕僪悢)偐傜扵嶕懍搙偑傢偐傝傑偡丅扵嶕僲乕僪悢傪尭傜偟偮偮丄nps傪岦忋偝偣傞偙偲偑廳梫偱偡丅儀儞僠儅乕僋偼廔斦扵嶕岦偗偲拞斦扵嶕岦偗偺2偮傪梡堄偟偰峴偆偲傛偄偱偟傚偆丅廔斦/拞斦嫟偵崅懍壔偡傞偙偲偑棟憐偱偡丅
懪偪庤偺恑峴偼堘偆偺偵丄壗庤偐愭偵摨偠嬊柺偑尰傟傞応崌偑偁傝傑偡丅嬊柺偑摨偠側傜偽偦偺嬊柺偺巕懛偺栘偼姰慡偵摨偠偵側傝傑偡偐傜丄埲慜偺扵嶕偺寢壥傪嵞棙梡偡傞偙偲偱扵嶕偺岠棪傪忋偘傞偙偲偑偱偒傑偡丅嬊柺偺忬懺偲摼揰傪曐懚偟偰偍偔偺偑抲姺昞(transposition table)偱偡丅
抲姺昞偼捠忢僴僢僔儏僥乕僽儖偲偟偰幚憰偝傟傑偡丅spot偱偼丄僆乕僾儞僴僢僔儏(chaining偵傛傞僴僢僔儏僥乕僽儖)傪梡偄偰偄傑偡丅抲姺昞偱偼丄乽梫慺偺嶍彍偑婲偙傜側偄(昞慡懱偺僋儕傾偼偁傞偑丄梫慺1偮傪庢傝弌偟偰嶍彍偡傞偙偲偼側偄)乿偲偄偆慜採偑偁傝傑偡偺偱丄僋儘乕僘僪僴僢僔儏傪梡偄傞偺傕傛偄偱偟傚偆丅傑偨丄僴僢僔儏抣偺徴撍偑婲偙偭偨偲偒丄椉幰傪奿擺偡傞搘椡傪偣偢丄婛懚偺僨乕僞偼忋彂偒偟偰偟傑偆偲偄偆曽朄傕偁傝傑偡丅抲姺昞偺惈幙偐傜丄婛懚僨乕僞傪忋彂偒偟偰傕岠棪偑庒姳掅壓偡傞壜擻惈偑偁傞偩偗偱丄寢壥偼曄傢傜側偄偐傜偱偡丅
儃乕僪傪幆暿偡傞偨傔偵壗傜偐偺僴僢僔儏抣傪寁嶼偡傞昁梫偑偁傝傑偡丅堦斒揑側僴僢僔儏僥乕僽儖偲摨偠偔丄僴僢僔儏抣偼寁嶼偑崅懍偱丄偐偮堎側偭偨斦柺偼堎側偭偨抣偵曄姺偝傟傞偙偲偑朷傑偟偄偱偡丅
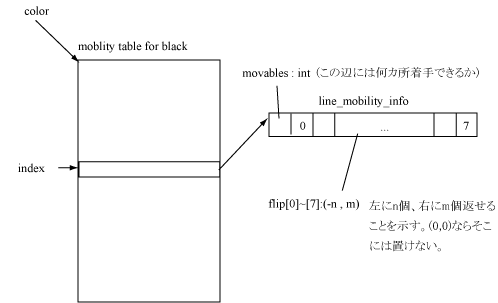
spot偱偼丄儃乕僪偑忢偵奺曈偺僀儞僨僢僋僗傪曐帩偟偰偄傞偙偲傪棙梡偟偰丄廲曈偺僀儞僨僢僋僗8屄(unsigned short * 8)傪尦偵僴僢僔儏抣傪寁嶼偟傑偡丅嬶懱揑偵偼丄i斣栚偺僀儞僨僢僋僗傪index[i]偲偡傞偲
hash = sum(index[i] * 17^i)
偲偄偆幃偱寁嶼偝傟傑偡丅17偼傾儖僼傽儀僢僩暥帤楍傪僴僢僔儏壔偡傞嵺偵傛偄偲偝傟偰偄傞儅僕僢僋僫儞僶乕偱丄壗偲側偔梡偄偰傒偨偲偙傠偦傟傑偱巊偭偰偄偨庤朄偵斾傋偰僴僢僔儏抣偺徴撍偑寑揑偵彮側偔側偭偨偨傔丄嵦梡偟偰偄傑偡丅
抲姺昞偵偼埲壓偺僨乕僞傪擖傟偰偄傑偡丅
廲曈偺僀儞僨僢僋僗偑8屄偁傟偽丄儃乕僪偺愇偺暲傃傪堦堄偵昞尰偡傞偙偲偑偱偒傑偡丅僀儞僨僢僋僗(0乣6560)偼16價僢僩偁傟偽廫暘昞尰偱偒傑偡偺偱丄16*8=128價僢僩+怓忣曬丄偱嬊柺傪奿擺偡傟偽傛偄偙偲偵側傝傑偡丅
拲堄偡傋偒偼奿擺偡傞摼揰偱偡丅alpha-beta扵嶕傪峴偆応崌丄巬姞傝偵傛偭偰僲乕僪偺惓妋側minimax抣偑掕傑傜側偄偙偲偑偁傝傑偡丅偙偺偨傔丄抲姺昞偵偼偦偺僲乕僪偑曉偡抣傪奿擺偡傞偩偗偱偼晄廫暘偱丄壗傜偐偺岺晇傪巤偡昁梫偑偁傝傑偡丅1偮偺曽朄偼丄乽恀偺minimax抣偑懚嵼偡傞斖埻乿傪奿擺偡傞曽朄偱偡丅恀偺minimax抣偲偼丄乽alpha-beta僇僢僩傪偟側偐偭偨応崌偺minimax扵嶕乿偵偍偄偰僲乕僪偵偮偔昡壙抣偺偙偲偱偡丅傕偆1偮偺曽朄偼丄乽抣乿偲偦偺乽庬椶(恀偺抣偱偁傞/忋尷偱偁傞/壓尷偱偁傞)乿傪奿擺偡傞傕偺偱偡丅spot偱偼慜幰偺乽恀偺昡壙抣偑懚嵼偡傞斖埻乿傪奿擺偟偰偄傑偡丅偮傑傝丄乽儃乕僪乿傪僉乕偲偟丄[忋尷, 壓尷]傪抣偲偡傞僴僢僔儏昞偱偡丅
扵嶕偺寢壥偲恀偺昡壙抣偺娭學偼埲壓偺傛偆偵側傝傑偡丅
忋尷偲壓尷偑堦抳偡傞応崌傪丄乽恀偺抣偑婛偵敾柧偟偰偄傞偙偲乿偺栚報偲偟偰偄傑偡丅
婛偵昡壙抣偺斖埻偑偁傞掱搙傢偐偭偰偄傞嬊柺偵懳偟偰偝傜偵扵嶕傪峴偄丄怴偨偵昡壙抣斖埻偑摼傜傟偨偲偟傑偡丅偙偺偲偒丄恀偺昡壙抣偼乽傕偲傕偲傢偐偭偰偄偨斖埻乿偲乽崱夞怴偨偵傢偐偭偨斖埻乿偺嫟捠晹暘偵懚嵼偟傑偡丅偙偺傛偆偵偟偰丄扵嶕傪孞傝曉偡偆偪偵恀偺昡壙抣偑懚嵼偡傞斖埻傪峣傝崬傫偱偄偔偙偲偑偱偒傑偡丅枹偩弌尰偟偰偄側偄嬊柺偺昡壙抣偼(-亣, +亣)偺斖埻偵偁傞偲峫偊傑偡丅
摨堦嬊柺偺嵞扵嶕傪杊偖偺偑抲姺昞偺栶栚丄偲彂偒傑偟偨偑丄幚嵺偺偲偙傠抲姺偑婲偙傝傗偡偄偲尵傢傟傞廔斦偵偍偄偰傕丄抲姺昞傪巊偭偰嶍尭偱偒傞僲乕僪悢偼慡懱偺1/3掱搙偱偡丅抲姺昞偺栶妱偼丄傓偟傠斀暅怺壔側偳偵偍偄偰慜夞偺扵嶕偱摼傜傟偨忣曬傪嵟戝尷棙梡偡傞丄偲偄偆偙偲偺曽偑戝偒偄偺偱偼側偄偐偲巚偄傑偡丅
抲姺昞傪巊偆嵺偼丄扵嶕栘偺忋偺曽偩偗偱巊偆傛偆偵偡傞偙偲偵拲堄偡傞昁梫偑偁傝傑偡丅慡偰偺僲乕僪傪奿擺偟偰偄偰偼丄偐偊偭偰懍搙偑掅壓偟傑偡偟丄怺偄扵嶕偵偍偄偰偼儊儌儕傪娙扨偵堨傟偝偣偰偟傑偄傑偡丅
忋偵弎傋偨乽minimax抣偺懚嵼斖埻傪奿擺偡傞乿僞僀僾偺抲姺昞傪梡偄偨応崌偺alpha-beta傾儖僑儕僘儉偺媅帡僐乕僪傪帵偟傑偡丅spot偺僐乕僪偱偼丄AI.cpp拞偺AlphaBetaAI::normal_alphabeta偱姰慡側幚憰傪尒傞偙偲偑偱偒傑偡丅(spot偺僐乕僪偼偝傜偵null window search傪慻傒崌傢偣偨傾儖僑儕僘儉偵側偭偰偄傑偡丅)
int alphabeta(int limit, int alpha, int beta)
{
if (limit == 0) return 昡壙抣; // 怺偝惂尷
尰嵼偺嬊柺傪抲姺昞偐傜専嶕偟偰[忋尷, 壓尷]傪庢傝弌偟; // 懚嵼偟側偗傟偽捛壛
// 埲壓丄乽忋尷乿乽壓尷乿偲偼偙偺抲姺昞偐傜庢傝弌偟偨抣偺偙偲傪偄偆
if (抲姺昞偵懚嵼) {
if (忋尷 <= alpha) return 忋尷; // alpha抣傪挻偊傛偆偑側偄偺偱扵嶕偟偰傕柍懯
if (壓尷 >= beta) return 壓尷; // beta抣傪昁偢挻偊偰偟傑偆偺偱扵嶕偟偰傕柍懯
if (忋尷 == 壓尷) return 忋尷; // 婛偵恀偺抣偑傢偐偭偰偄傞偺偱曉偡
// alpha-beta window傪側傞傋偔嫹偔偟偰岠棪up
alpha = max(alpha, 壓尷);
beta = min(beta, 忋尷);
}
/*
(杮摉偼偙偺傊傫偱僷僗偐偳偆偐偺張棟)
*/
int score;
int score_max = -亣; // 偙偺僲乕僪偱弌偨嵟戝抣
int a = alpha;
慡偰偺庤傪惗惉;
庤傪僜乕僩;
foreach (偦傟偧傟偺庤) {
庤傪懪偮;
score = -alphabeta(limit-1, -beta, -a);
庤傪栠偡;
if (score >= beta) {
// beta cut
抲姺昞偵[score, +亣)傪捛壛; // 恀偺昡壙抣偼[score, +亣)偺偳偙偐
return score;
}
if (score > score_max) {
a = max(a, score);
score_max = score;
}
}
if (score_max > alpha)
抲姺昞偵[score_max, score_max]傪捛壛; // 恀偺昡壙抣偼score_max偲敾柧偟偨
else
抲姺昞偵(-亣, score_max]傪捛壛; // 恀偺昡壙抣偼(-亣, score_max]偺偳偙偐
return score_max;
}
(娭悢偵搉偝傟偨)alpha抣偲丄乽巕僲乕僪偺嵟戝抣(score_max)乿傪嬫暿偡傞偙偲偑廳梫偱偡丅巕僲乕僪偺抣偑偳傟傕alpha傪墇偊側偐偭偨応崌偵嵎偑偱偰偒傑偡丅抲姺昞偵斖埻傪奿擺偡傞嵺偵偙偺2偮傪嬫暿偟偰偄側偄偲丄扵嶕偑惓偟偔婡擻偟傑偣傫丅傑偨丄巕僲乕僪偺抣偑偳傟傕alpha傪墇偊側偐偭偨応崌alpha傪曉偡偙偲偲score_max傪曉偡偙偲傪斾妑偡傞偲丄屻幰偺曽偑傛傝恀偺昡壙抣偺斖埻偵嬤偄忣曬傪採嫙偱偒傞偺偱丄寢壥偲偟偰巬姞傝偑懡偔敪惗偟丄扵嶕偑崅懍壔偝傟傑偡丅偙偺傛偆側丄側傞傋偔懡偔偺忣曬傪扵嶕偺曉傝抣偲偟偰曉偡惈幙傪fail-soft偱偁傞偲偄偄傑偡丅
spot偱偼丄偐偺桳柤側Michael Buro巵偺榑暥"Experiments with Multi-ProbCut and a New High-Quality Evaluation Function for Othello"偵帵偝傟偨傾僀僨傿傾傪梡偄偰昡壙娭悢傪幚憰偟偰偄傑偡丅
spot偺昡壙娭悢偱偼丄斦柺偺忬懺偐傜偦傟埲崀嵟慞庤傪懪偭偨応崌偺嵟廔揑側愇嵎傪梊憐偟傑偡丅
IOS偺懳嬊偐傜30枩婝晥丄Logistello's book skelton偺12枩婝晥傪崌傢偣偰巊梡丅IOS偺婝晥偵偮偄偰偼廔斦15乣17庤偺姰慡撉傒愗傝傪峴偭偰婝晥拞偺岆傝傪掶惓偟偰巊梡偟偰偄傑偡丅
spot偱偼埲壓偺摿挜(feature)傪昡壙偟偰偄傑偡丅偦傟傜偺摼揰偼丄婝晥僨乕僞拞偺寢壥偐傜夞婣暘愅傪峴偆偙偲偵傛傝嶼弌偝傟傑偡丅
拝庤壜擻庤悢偺嬤帡抣偲偟偰丄乽偁傞曈偵壗僇強抲偗傞偐乿偲偄偆悢抣傪梡偄偰偄傑偡丅偙偺庬偺嬤帡抣偼惓妋側拝庤壜擻庤悢傪媮傔傞偺偲斾妑偟偰旕忢偵崅懍偱丄偐偮傛偄嬤帡傪梌偊傞偙偲偑幚尡揑偵抦傜傟偰偄傑偡丅傑偨spot偵偍偄偰偼丄拝庤壜擻埵抲偺昡壙偼奺僷僞乕儞偺昡壙抣偵帠慜偵寁嶼偝傟偰杽傔崬傑傟偰偄傞偺偱丄拝庤壜擻埵抲偺寁嶼偵偼幚幙僐僗僩偑偐偐傝傑偣傫丅
偟偐偟側偑傜丄夞婣暘愅傪峴偆偲丄拝庤壜擻埵抲偼僎乕儉彉斦偵偍偄偰桳岠側巜恓偱偁傞傕偺偺丄20庤栚晅嬤偐傜偳傫偳傫寢壥傊偺婑梌偑彫偝偔側傝丄0偵廂懇偟偰偟傑偆偙偲偑傢偐傝傑偟偨丅偙傟偼丄僎乕儉偑屻敿偵峴偔偵廬偭偰婝晥拞偵弌尰偡傞僷僞乕儞偺庬椶偑憹偊丄拝庤壜擻庤悢偵傛傞桪楎傕娷傔偰僷僞乕儞偺摼揰偲偟偰愢柧偝傟傞傛偆偵側傞寢壥偱偁傞偲峫偊傜傟傑偡丅
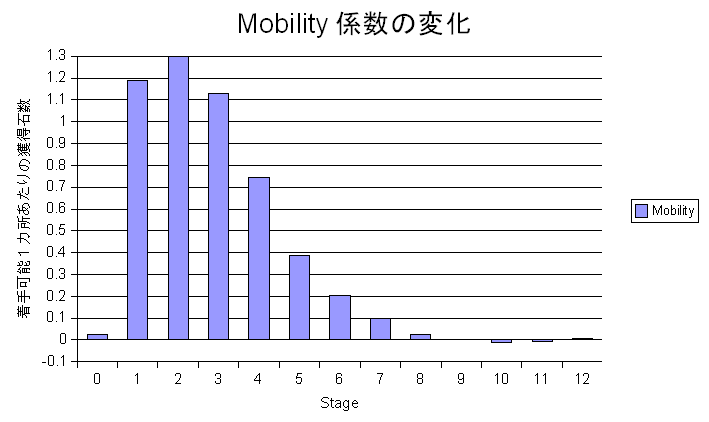
壓恾偵偍偄偰丄stage偼儕僶乕僔偺恑峴慡60庤傪4偱妱偭偨悢抣偱偡丅stage 13埲崀偼傎傏0偑懕偔偨傔徣棯偟偰偄傑偡丅廲幉偼1僇強懪偰傞応強偑偁傞偲壗愇嵎暘桳棙偐傪帵偟傑偡丅
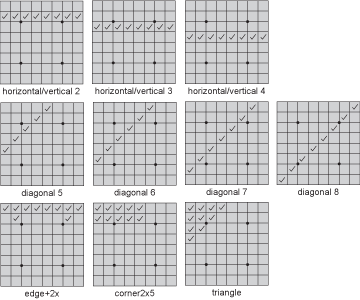
奺僷僞乕儞偼堦堄側僀儞僨僢僋僗偱幆暿偝傟傑偡丅庡梫側廲丒墶丒幬傔曈偺僀儞僨僢僋僗偼儃乕僪偑婛偵帩偭偰偄傞偺偱丄昡壙娭悢偱偼偦傟傜偲丄偦傟傜偵懡彮廃埻偺儅僗傪壛偊偨僀儞僨僢僋僗傪寁嶼偟偰僥乕僽儖偐傜摼揰傪撉傒丄壛嶼偟傑偡丅椺偊偽edge2x僷僞乕儞偺僀儞僨僢僋僗偱偁傟偽丄horizontal/vertical 1偺僀儞僨僢僋僗傪儃乕僪偑婛偵帩偭偰偄傞偺偱丄偦傟偵2偮偺X偺抣傪壛偊傞偙偲偱嶌傞偙偲偑壜擻偱偡丅
傑偨丄拝庤壜擻庤悢偺嬤帡抣偲偟偰曈傊偺拝庤壜擻悢傪尒偰偄傞偙偲偐傜丄拝庤壜擻庤悢偵傛傞摼揰偼曈偺摼揰偲尒傞偙偲偑偱偒傑偡丅偙偺偨傔丄拝庤壜擻庤悢偵娭偡傞摼揰偼曈偺摼揰偵帠慜偵杽傔崬傓偙偲偑偱偒丄夞婣寁嶼偵傛傞曈偺昡壙抣偲丄拝庤壜擻庤悢偵傛傞昡壙抣傪崌寁偟偰曈偺摼揰偲偟傑偡丅
偝偰丄奺僷僞乕儞偵偮偄偰丄摼揰傪媮傔傞昁梫偑偁傝傑偡丅嬶懱揑偵偼椺偊偽丄乽edge+2X僷僞乕儞偺僀儞僨僢僋僗13102偼壗愇暘偵憡摉偡傞偐丠乿偲偄偆抣傪媮傔傞偙偲偵側傝傑偡丅
偙偺抣偼夞婣暘愅偵傛偭偰媮傔傑偡丅嫵巘怣崋偲側傞婝晥僨乕僞偵懳偟偰丄昡壙娭悢偑梊憐偡傞抣偲幚嵺偺寢壥偲偺岆嵎偺擇忔偑嵟彫偵側傞傛偆偵僷儔儊乕僞傪挷惍偟偰傗傞傢偗偱偡丅愢柧曄悢偑悢廫枩屄偵偺傏傞偨傔丄嵟媫崀壓朄傪梡偄偰抜奒揑偵挷惍偟偰偄偔偙偲偵側傝傑偡丅
嵟媫崀壓朄偼偟偽偟偽嬊強夝偵娮傝傗偡偄偲偟偰寚揰偑巜揈偝傟傑偡偑丄儕僶乕僔偺昡壙娭悢偵偍偄偰偼(宱尡揑帠幚偱偡偑)慡偰偺弶婜抣傪0偲偟偰妛廗傪偼偠傔傟偽懨摉側昡壙娭悢偑偱偒偁偑傝傑偡丅
昡壙娭悢偺妛廗偵偮偄偰偼丄偙偪傜偺暥彂傕嶲峫偵偟偰偔偩偝偄仺儕僶乕僔偺昡壙娭悢偺嵟揔壔
彉斦偼桳棙偲側傞攝抲偱傕丄廔斦偵偍偄偰傕摨條偵桳棙偱偁傞偲偄偆曐徹偼偁傝傑偣傫丅偙偺偨傔丄儕僶乕僔偺恑峴慡60庤傪4庤偛偲偵嬫愗偭偰15僗僥乕僕偵暘偗丄僗僥乕僕偛偲偵偦傟偧傟偺僷僞乕儞偺昡壙抣傪媮傔傑偡丅
傑偨丄僷僞乕儞偵傛偭偰偼嵍塃懳徧偁傞偄偼夞揮懳徧偲偄偭偨懳徧宍偑懚嵼偟傑偡丅懳徧側僷僞乕儞偵偼摉慠摨偠昡壙抣偑偮偔傋偒偱偁傞偲偄偆峫偊偵婎偯偒丄妛廗帪偵偼慡晹偺僷僞乕儞傪懳徧宍偺偆偪僀儞僨僢僋僗偺抣偑彫偝偄曽偵惓婯壔偟偰僇僂儞僩偟丄嵟屻偵僀儞僨僢僋僗偑戝偒偄曽偵傕偦偺妛廗寢壥傪僐僺乕偟偰偄傑偡丅偙偺傛偆偵偡傞偙偲偱丄乽懳徧宍偵摨偠摼揰偑偮偔乿偲偄偆岠壥偺懠偵乽奺僷僞乕儞偺弌尰昿搙傪懡偔偡傞偙偲偑偱偒丄妛廗偺怣棅搙偑崅傑傞乿偲偄偆岠壥偑摼傜傟傑偡丅
僗僥乕僕暘偗偺寢壥丄僗僥乕僕偑曄傢傞偲昡壙抣偑戝偒偔曄傢傞偲偄偆偙偲偑峫偊傜傟傑偡丅庤悢偵偟偰1庤暘偟偐曄傢傜側偄偺偵丄昡壙抣偑戝偒偔堎側傞偙偲偼峫偊偵偔偄偙偲偱偡丅偙偺栤戣傪夝寛偡傞偨傔偵丄杮棃偦偺僗僥乕僕偵僇僂儞僩偝傟傞4庤暘偺婝晥偺懠偵丄杮棃偼椬愙偟偨僗僥乕僕偵懏偡傞庤悢偺嬊柺傕暪偣偰崌寁6庤暘偺嬊柺傪擖椡偲偟偰妛廗傪峴偭偰偄傑偡丅
(偁偲偱偪傖傫偲彂偔)
(偁偲偱偪傖傫偲彂偔)
摉慠側偑傜婝晥拞偵慡偔弌尰偟側偐偭偨僷僞乕儞偵偮偄偰偼昡壙偺偟傛偆偑偁傝傑偣傫偺偱丄0揰偲偣偞傞傪摼傑偣傫丅偟偐偟側偑傜杮摉偼偦偺暲傃偼偲偰傕傛偄暲傃偱偁傞偐傕抦傟偢丄媡偵偲偰傕埆偄暲傃偱偁傞壜擻惈傕偁傝傑偡丅偦偺偨傔偵丄嬊柺偺昡壙傪岆傞壜擻惈傕偁傝傑偡丅
乽婝晥拞偵弌尰偟側偐偭偨僷僞乕儞偼偦傕偦傕廳梫搙偑掅偄偺偱娭學側偄乿偲偄偆峫偊曽傕偁傝傑偡偑丄峀戝側僎乕儉栘扵嶕嬻娫偺拞偵偼憡摉堎忢側庤傕娷傑傟偰偍傝丄(憃曽偑偦傟側傝偵傑偲傕側庤傪懪偮偙偲偑懡偄偲巚傢傟傞)婝晥偐傜偱偼妛廗偱偒側偄嬊柺偑懚嵼偡傞壜擻惈傕斲掕偱偒傑偣傫丅
偙偺栤戣傪夝寛偡傞偨傔偺曽朄偲偟偰丄偡偱偵摼揰偺傢偐偭偰偄傞僷僞乕儞傪巊偭偰愇偺暲傃偐傜摼揰傪梊憐偡傞僯儏乕儔儖僱僢僩儚乕僋傪峔抸偟丄偦傟傪梡偄偰枹抦偺僷僞乕儞偺摼揰傪梊憐偡傞偲偄偆庤朄偑Keyano偺嶌幰偵傛偭偰採埬偝傟偰偄傑偡丅
妛廗偺寢壥偱偒偁偑偭偨昡壙娭悢偑壥偨偟偰埲慜傛傝傕傛偔側偭偨偺偐埆偔側偭偨偺偐丄偒偪傫偲昡壙偡傞昁梫偑偁傝傑偡丅昡壙娭悢偺昡壙偺偨傔偵偼丄昡壙娭悢傪廮擃偵庢傝懼偊傜傟傞傛偆偵巚峫儖乕僠儞傪愝寁偟偰偍偒丄堎側傞昡壙娭悢摨巑傪愴傢偣偰彑攕傪尒傑偡丅
嬶懱揑偵偼丄random opening丄偮傑傝嵟弶偺悢庤傪儔儞僟儉偵懪偭偨帪揰偐傜帋崌傪偼偠傔傑偡丅1偮偺opening偵偮偄偰愭庤丒屻庤傪擖傟懼偊偰2帋崌傪峴偄傑偡丅偙傟傪丄100opening傕偟偔偼1000opening掱搙偺懡偔偺嬊柺偵懳偟偰峴偄傑偡丅朿戝側帋崌傪偙側偡昁梫偑偁傞偨傔丄僋儔僗僞摍偺娐嫬偑偁傞偲曋棙偱偡丅奺帋崌偼姰慡偵撈棫側偺偱丄奺CPU偵僕儑僽傪搳偘偰暲楍偵幚峴偝偣傞偙偲偑偱偒傑偡丅
昡壙偺尨棟偼偙偆偱偡丅random opening屻偺嬊柺偑梌偊傜傟偨帪揰偱丄憃曽偑嵟慞傪懪偭偨応崌偺彑攕偼寛偟偰偄傞偼偢偱偡丅傛偭偰2偮偺昡壙娭悢偑摨偠嫮偝偩偲偟偨傜丄慡帋崌拞偺彑偪偲晧偗偺夞悢偑摨悢偵側傞偼偢偱偡丅彑偪晧偗偺夞悢偺曃傝傪尒傞偙偲偱丄偳偪傜偺昡壙娭悢偑傛偄偐傪敾抐偟傑偡丅 偦偺嵎偑桳堄側傕偺偱偁傞偐丄偨偩悢帤傪尒傞偩偗偱偼側偔丄摑寁揑偵専掕傪峴偆偙偲偑昁梫偱偡丅
掕愇偼彉斦偺懪偪娫堘偄傪杊偄偱晄棙側揥奐偵娮傞偺傪杊偓丄傑偨掕愇偵忔偭偰偄傞娫偼扵嶕偑晄梫側偨傔崅懍壔偵傕峷專偟傑偡丅帩偪帪娫堦掕偺懳嬊偺応崌偼掕愇傪梡偄傞偙偲偱丄偦傟埲崀偺拞斦乣廔斦偵傛傝懡偔偺帪娫傪妱偗傞傛偆偵側傝傑偡丅
偟偐偟側偑傜丄尰嵼偺Thell偼傑偩掕愇傪幚憰偟偰偄傑偣傫丅偙傟偼丄Thell3奐敪偺摦婡偲側偭偨妛壢撪僆僙儘僾儘僌儔儈儞僌僐儞僥僗僩偵偍偄偰掕愇偺巊梡偑嬛偠傜傟偰偄偨偙偲丄幚憰偡傞梋桾偑側偐偭偨偙偲丄傑偨掕愇傪帺暘偱惗惉偱偒傞傛偆側僔僗僥儉傪峔抸偟偨偄偲峫偊偰偄傞偙偲丄摍偺棟桼偵傛傝傑偡丅
Thell偺幚憰偵偁偨偭偰丄懡偔偺曽乆偺彆尵偵傛偭偰條乆側傾僀僨傿傾傪摼偨傝丄媍榑傪怺傔傞拞偱怴偟偄傾僀僨傿傾傪惗傒弌偟偨傝偡傞偙偲偑偱偒傑偟偨丅姶幱偺堄傪崬傔偰丄偙偙偵婰偟偨偄偲巚偄傑偡丅
Copyright (C) 2001-2007 Seal Software <sealsoft AT sealsoft.jp>